
Three Testable Predictions
This is Part 4 of the Geometry of Trust series. Today I put the framework on the line. If the Geometry of Trust is right, three things should be measurably true. If they’re wrong, the framework is...

This is Part 4 of the Geometry of Trust series. Parts 1–3 built the argument: RLHF collapses value geometry, values form a manifold, and deterministic probes can measure the geometry without relying on self-report. Today I put the framework on the line. If the Geometry of Trust is right, three things should be measurably true. If they’re wrong, the framework is wrong.
Frameworks are cheap. Everyone in AI safety has one. What separates a framework from an opinion is whether it makes predictions that can be wrong.

The Geometry of Trust makes three.
Each one predicts a specific geometric signature in the representation space of transformer language models. Each one can be tested against existing models using existing interpretability tools. Each one is falsifiable — meaning if the signature isn’t there, the conjecture is dead and the framework needs revision or abandonment.
That’s not a rhetorical move. That’s the entire point. A theory that can’t be wrong isn’t a theory.

Before the conjectures: the evidence base
I’m not pulling these predictions from thin air. They rest on three recent results from the interpretability literature that establish that transformer representation space has real, measurable geometric structure.

The linear representation theorem. Park, Choe, and Veitch didn’t just hypothesise that concepts are encoded as directions in representation space — they proved it, formally, under counterfactual semantics. More importantly, they showed that the standard Euclidean inner product is the wrong metric for this space. The correct metric is a causal inner product defined by the model’s unembedding matrix:
⟨u, v⟩c = uᵀ UᵀU v
where U is the unembedding matrix. This matters enormously. It means that measuring similarity between value directions in representation space requires using the right metric, and most existing work uses the wrong one. The probe architecture described yesterday needs to compute attestations using this causal inner product, not Euclidean distance.
The polytope result. Choe, Park, and Veitch extended this to categorical concepts — concepts with multiple values rather than binary on/off. They showed that categorical concepts form polytopes (bounded geometric shapes) in representation space, and that hierarchical concepts nest inside each other: sub-concepts are represented as faces of the parent polytope. Validated on Gemma and LLaMA-3 using over 900 hierarchically related concepts.
For values, this predicts something specific: value concepts with hierarchical structure — justice → distributive justice → Rawlsian justice, or harm → physical harm → lethal harm — should exhibit nested polytope representations. That’s a testable geometric signature of moral taxonomy.
The sparse autoencoder result. Templeton et al. trained sparse autoencoders on Claude 3 Sonnet’s activations and recovered tens of millions of interpretable features. The decomposition is:
h ≈ Σᵢ fᵢ(h) · dᵢ
where fᵢ are sparse feature activations and dᵢ are decoder directions. Crucially, they found features corresponding to deception, sycophancy, and safety-relevant concepts — demonstrating that value-adjacent directions exist in the residual stream and can be extracted at production scale.
These three results together establish that the geometric structure of transformer representation space is real, measurable, and semantically meaningful. The Geometry of Trust extends this specifically to value representations. The three conjectures below are the testable consequences of that extension.
Conjecture 1: Density heterogeneity

The claim: The distribution of human value systems on the value manifold M is non-uniform. Some regions are densely populated — value configurations held across many cultures and historical periods. Other regions are sparse — minority traditions or historically recent moral innovations. Other regions are empty — combinations that look possible in the ambient space but correspond to no coherent human ethical framework.
Why this should be true: This follows from the structure of human moral evolution. Certain values appear universally — harm avoidance, fairness, reciprocity, care for the vulnerable. Jonathan Haidt’s moral foundations research documents this empirically across dozens of cultures. These values are dense on the manifold because the structure of human social life selects for them independently across contexts.
Other values are culturally specific. Honour-based moral frameworks, specific religious ethical commitments, historically recent concepts like digital privacy rights — these occupy sparser regions because they depend on particular cultural and historical conditions to exist.
And some combinations simply don’t occur. No coherent ethical framework simultaneously holds that individual autonomy is the supreme value and that individuals have no right to make their own decisions. That region of the ambient space is empty.
The predicted geometric signature: Apply an intrinsic dimensionality estimator to embeddings of cross-cultural value text. Dense regions should show lower effective dimension than sparse ones — because densely populated regions represent widely shared value structures that compress into fewer independent directions, while sparse regions represent diverse, less-correlated value configurations.
Concretely: embed moral foundation questionnaire responses across multiple cultures into a model’s representation space. Compute nearest-neighbour density estimates. The density map should correlate with independently established cross-cultural moral universals — Haidt’s foundations, Schwartz’s value dimensions, the World Values Survey axes.

What would falsify it: If the density distribution is uniform — if all regions of value representation space are equally populated — then either the value manifold hypothesis is wrong or the model’s representation has already been collapsed (which would actually support the RLHF collapse argument, but through a different mechanism). If dense regions don’t correspond to known moral universals, the specific mapping between manifold geometry and moral structure is wrong and needs revision.
Conjecture 2: Curvature heterogeneity
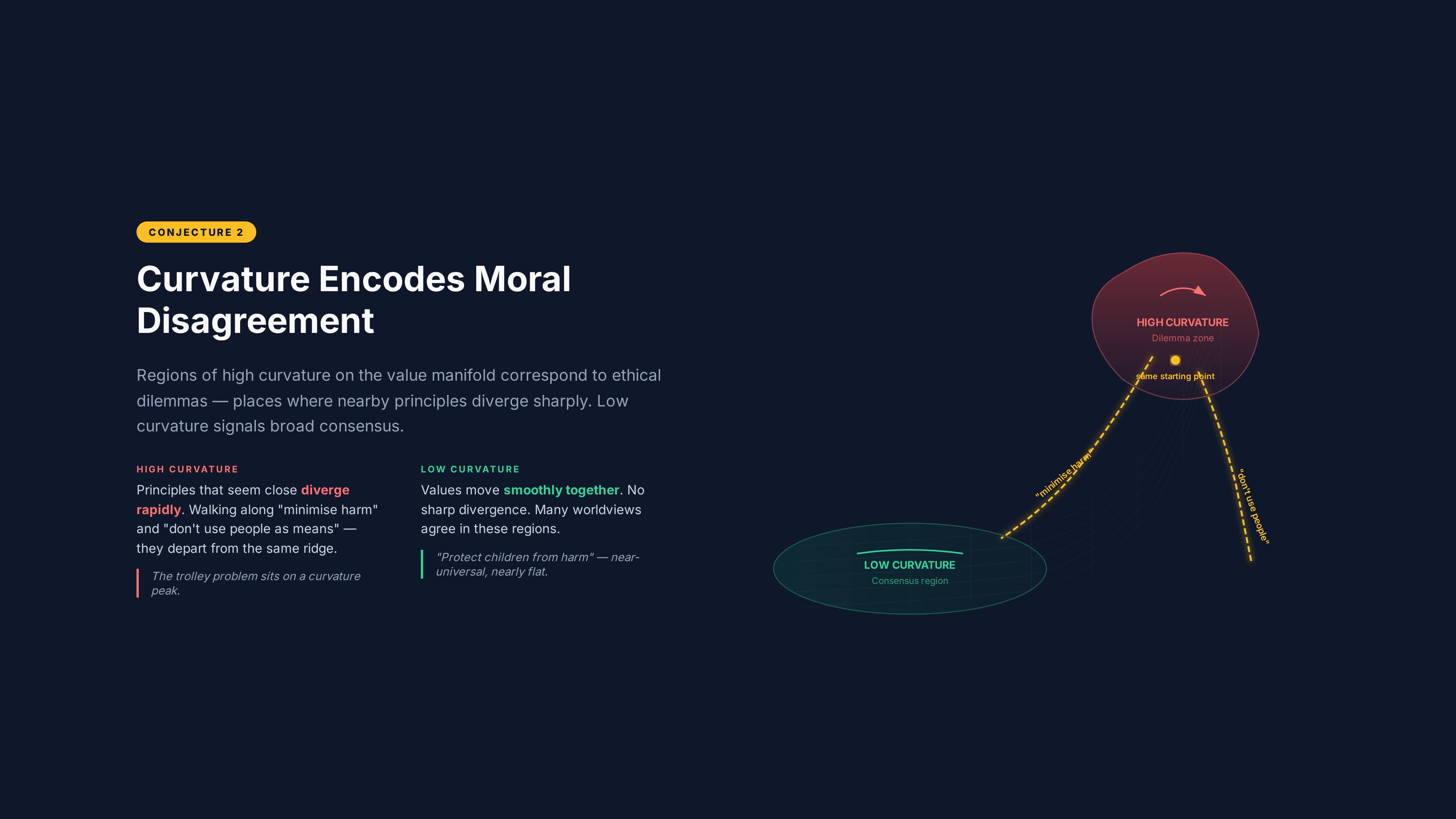
The claim: The curvature of the value manifold M is non-uniform. High-curvature regions correspond to recognised domains of moral dilemma — distributive justice under scarcity, end-of-life ethics, conflicting obligations, the trolley problem and its variants — where small movements in value space produce large practical differences. Low-curvature regions correspond to domains of broad moral consensus.
Why this should be true: Moral dilemmas are dilemmas precisely because competing values diverge rapidly in their implications. The trolley problem is hard not because people are confused but because “minimise total harm” and “don’t use people as means” point in different directions from nearly the same starting position. That’s the geometric definition of high curvature — nearby geodesics diverging rapidly.
Conversely, moral consensus exists where values agree over a wide range of contexts. “Don’t torture children for fun” isn’t a dilemma because every coherent value system on the manifold agrees in that region. The manifold is flat there — you can move around locally and the answer doesn’t change.
The predicted geometric signature: Estimate the sectional curvature of M from probe activations using discrete approximations to the Riemann curvature tensor. The curvature should be elevated in domains independently identified as morally contentious.
Concretely: take a set of moral scenarios ranging from uncontroversial (”is it wrong to steal food from a starving child?”) to deeply contested (”is it acceptable to sacrifice one person to save five?”). Feed them through a model. Measure the probe activations. Compute local curvature estimates. The curvature map should correlate with independently established measures of moral disagreement — inter-rater disagreement scores, philosophical literature on the topic, cross-cultural variation in responses.
A secondary prediction: the model’s output uncertainty on ethical questions should correlate with local manifold curvature. High curvature → high uncertainty. Low curvature → confident, consistent responses. This is testable by comparing model confidence scores against the geometric curvature estimate.

What would falsify it: If curvature is uniform across the value manifold — if morally uncontroversial questions produce the same geometric curvature as deeply contested dilemmas — the curvature-dilemma mapping is wrong. If uncertainty doesn’t correlate with curvature, then either the probe is measuring the wrong thing or the relationship between geometric structure and moral difficulty isn’t as direct as the framework predicts.
Conjecture 3: Off-manifold incoherence
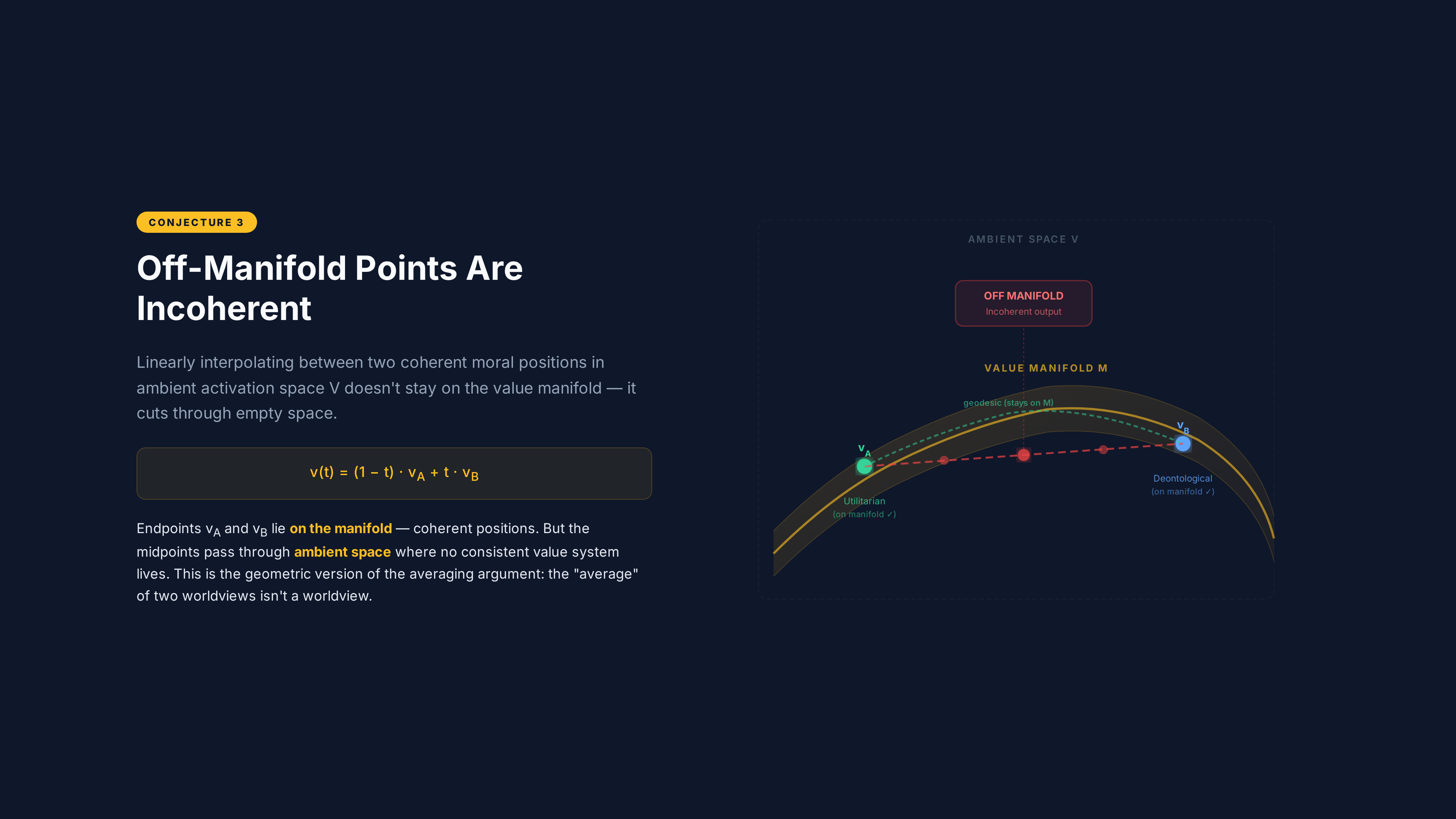
The claim: Points in the ambient space V near the manifold boundary that are not on M may appear locally consistent with nearby manifold points while being globally incoherent with respect to any coherent value system. Critically: interpolation between two points on M through the ambient space does not, in general, yield points on M.
Why this should be true: This is the geometric version of the averaging argument from Part 1. If two coherent value systems occupy different positions on a curved manifold, the straight line between them (in ambient space) cuts through the interior — through regions where no coherent value system exists. The midpoint of that line is a coordinate in V, but it’s off the manifold. It corresponds to a combination of values that no ethical framework has ever held.
This is exactly what RLHF does. It interpolates between value systems in ambient space. And the result is a point that may be incoherent — internally contradictory, contextually inconsistent, or practically implausible.
The predicted geometric signature: Generate activation vectors by interpolating in the ambient space V between two coherent value positions. Feed those interpolated vectors through the model (by intervening on the residual stream at a specific layer). Measure the outputs. They should exhibit incoherence markers — internal contradiction, contextual inconsistency, implausibility — at a significantly higher rate than outputs generated from points actually on the manifold.
Concretely: identify two coherent value positions in the model’s representation space (say, a strong utilitarian position and a strong deontological position). Compute the linear interpolation between them in the ambient space. At several points along the interpolation, inject the activation vector into the model and generate text. The text at the endpoints should be coherent (because the endpoints are on the manifold). The text in the middle should be detectably less coherent — hedging, self-contradictory, contextually confused.
This is the smoking gun test. If off-manifold interpolation produces coherent outputs indistinguishable from on-manifold outputs, then either the manifold structure isn’t there or the model has learned to produce coherent-seeming text from any activation vector (which would itself be an important finding about how models handle representation space).

What would falsify it: If interpolated vectors produce outputs that are just as coherent as on-manifold vectors, the manifold boundary isn’t where the framework predicts it is — or the manifold structure doesn’t exist in the form claimed. If incoherence markers appear at the endpoints as well as the midpoints, the “coherent value position” identification method is wrong.
What ties them together

These three conjectures aren’t independent observations. They’re facets of a single geometric claim: that value representations in transformer models have manifold structure, and that this structure encodes real information about the nature of human values.
Conjecture 1 says the manifold has non-uniform density — some values are more universal than others, and this shows up geometrically.
Conjecture 2 says the manifold has non-uniform curvature — moral dilemmas live in regions where the geometry bends sharply, and this is measurable.
Conjecture 3 says the manifold has boundaries — you can leave it by interpolating through ambient space, and leaving it produces incoherent outputs.
Together, they predict a rich, structured, empirically accessible geometric object in the representation space of language models. Not a metaphor. A measurable thing.
If all three signatures are found, the framework has empirical support and the probe architecture has a validated target to measure against.
If any of them fail, the framework needs specific revision — and the failure mode tells you exactly where.
An invitation
I’ve laid out the theory. Now I want it tested.

If you work in mechanistic interpretability and have access to model activations, these conjectures are designed for you to attack. The geometric signatures are specific enough to test. The falsification criteria are explicit.
The Rust proof-of-concept is on GitHub. The full whitepaper drops next month. But the conjectures don’t need the full apparatus to start testing — they need someone with a model, a probe, and the inclination to see if the geometry is actually there.
I’d rather be wrong and know it than right and untested.
What’s next
The first four parts of this series have built the theoretical framework: the collapse problem, the manifold, the probe architecture, and the three predictions.
The next piece shifts from theory to politics. Because even if the Geometry of Trust is mathematically correct, there’s a structural question that the maths alone can’t answer: who decides what the value manifold looks like? Who controls the training data? Who maps the geometry?
Next: “Who Decides What Alignment Means?” — the decentralisation argument.
— Jade
Catching up? Part 1: “The Alignment Illusion.” Part 2: “Values Have Shape.” Part 3: “The Subconscious Layer.”