
Values Have Shape: An Introduction to the Value Manifold
This is Part 2 of the Geometry of Trust series. Today I’m going to explain what that structure actually is, mathematically, and why “manifold” isn’t just a fancy word I’m using to sound clever.

This is Part 2 of the Geometry of Trust series. Yesterday I argued that RLHF collapses the full structure of human values into a single averaged point — producing AI that’s honest to no one. Today I’m going to explain what that structure actually is, mathematically, and why “manifold” isn’t just a fancy word I’m using to sound clever.
Yesterday’s piece ended with a claim: values have shape.

Not metaphorically. Not poetically. Mathematically.
Today I need to make that precise. Because if you’re going to follow the rest of this series — the probe architecture, the three conjectures, the decentralisation argument — you need to understand what a value manifold is, what it means for it to have curvature, and why that curvature is where all the interesting problems live.
I’ll keep the notation minimal. But I won’t dumb down the ideas.
What’s a manifold?
Start with the simplest version.
A manifold is a space that looks simple when you zoom in but has complex structure when you zoom out. The canonical example is Earth’s surface. Stand in a field and it looks flat. Walk a hundred metres in any direction and it still looks flat. But zoom out far enough and you discover it wraps around itself, has no edges, and can’t be flattened onto a table without tearing or distorting something.

That’s a 2-dimensional manifold embedded in 3-dimensional space. Locally flat, globally curved.
The mathematical definition generalises this: an n-dimensional manifold is a space where every point has a neighbourhood that looks like ordinary n-dimensional Euclidean space. You can do calculus in that neighbourhood — measure distances, compute derivatives, draw tangent lines — but the global shape might be wildly different from anything Euclidean.
Why does this matter for values?
The ambient space vs the manifold
Imagine the full space of all possible value configurations. Every conceivable combination of moral commitments, ethical priorities, and value weightings. Call this space V.
V is enormous and mostly empty.
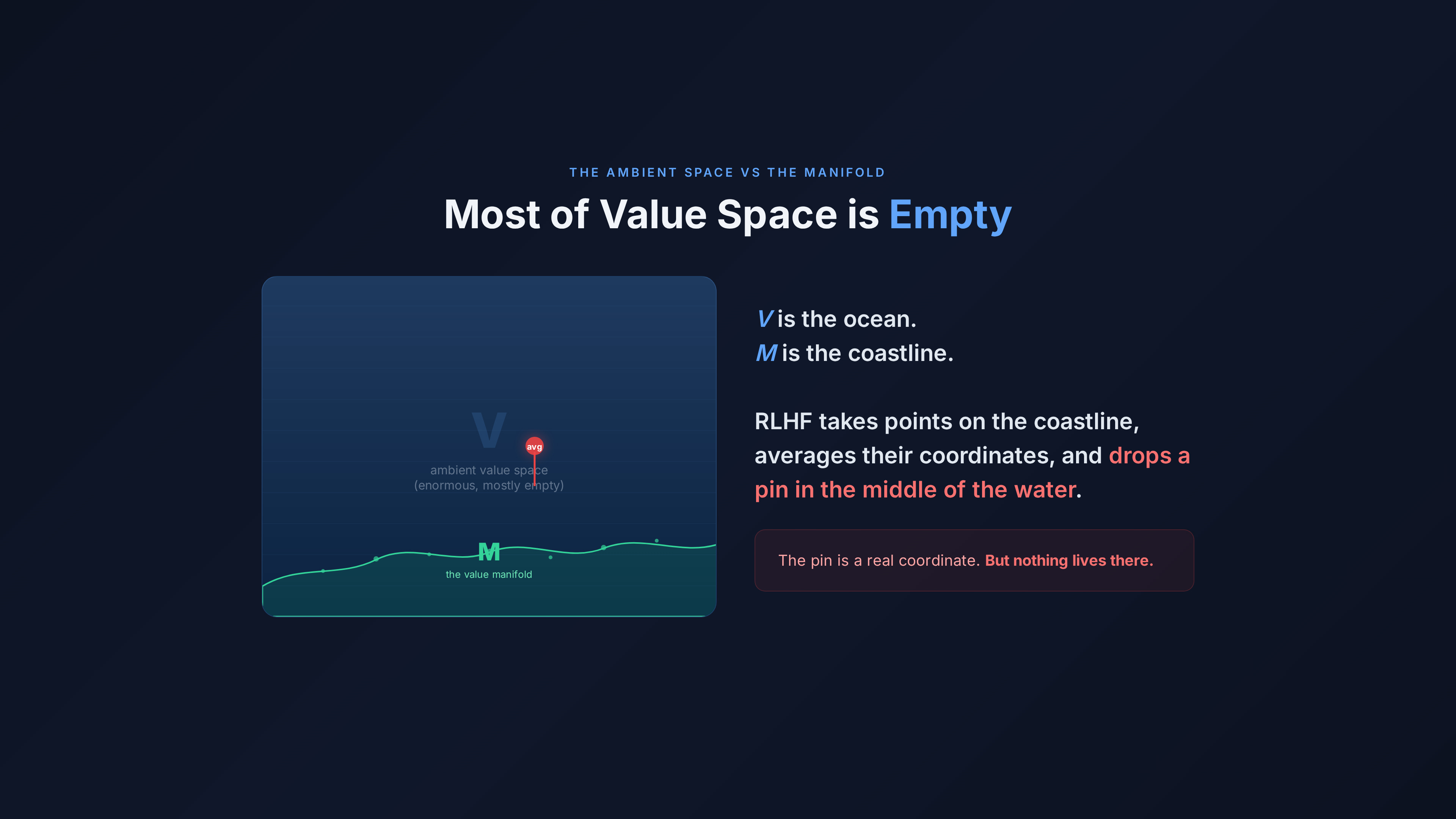
Most combinations of values are incoherent. A value system that simultaneously holds “human life is sacred” and “murder is morally neutral” doesn’t correspond to any ethical framework anyone has ever held or could hold. That combination exists as a coordinate in V, but it’s empty space — noise, not signal.
Real human value systems occupy a much smaller subspace of V. They cluster on a lower-dimensional surface — a manifold M embedded in V — shaped by millennia of cultural evolution, philosophical development, and lived moral experience.
Think of it this way. V is the ocean. M is the coastline. RLHF takes a bunch of points on the coastline, averages their coordinates, and drops a pin in the middle of the water. The pin is a real coordinate. But nothing lives there.
What gives the manifold its shape?
Three properties define the geometry of M, and each one maps to something real about how values work.
Density. Some regions of M are densely populated — many coherent value systems cluster there. These are the near-universals: harm avoidance, fairness, reciprocity, care for the vulnerable. They appear across virtually every human culture not because someone decreed them but because the structure of human social life selects for them. Other regions are sparse — the culturally specific commitments that only certain traditions hold. And between the populated regions, there are empty zones where no coherent value system exists.

The density distribution on M tells you something fundamental: which values are structurally robust (they keep appearing independently across cultures) and which are contingent (they depend on specific historical and cultural conditions to exist).
Curvature. This is where it gets interesting.
Curvature measures how much the manifold bends. In flat regions, nearby value systems are similar — small changes in your moral commitments produce small changes in practical outcomes. Move slightly along the manifold and you end up somewhere recognisable.
In high-curvature regions, the opposite is true. Small changes in your starting position produce dramatically different outcomes. The manifold bends sharply, and two value systems that are geometrically close can point in completely different practical directions.

These high-curvature regions are the moral dilemmas.
The trolley problem isn’t hard because people are confused. It’s hard because it lives in a region of the value manifold where the surface bends sharply — where the commitment to “minimise harm” and the commitment to “don’t use people as means” diverge rapidly even though they’re locally close. You’re standing on a ridge where a single step in either direction takes you somewhere completely different.
This is a testable prediction, by the way. If the value manifold hypothesis is correct, then a model’s uncertainty on ethically contested questions should correlate with the local curvature of its value representation. High curvature = high uncertainty. Low curvature = confident, consistent responses. That’s Conjecture 2 of the framework, and I’ll spell it out properly in Part 4.
Topology. Curvature describes how the manifold bends locally. Topology describes its global shape — whether it has holes, whether it’s connected, whether it wraps around itself.
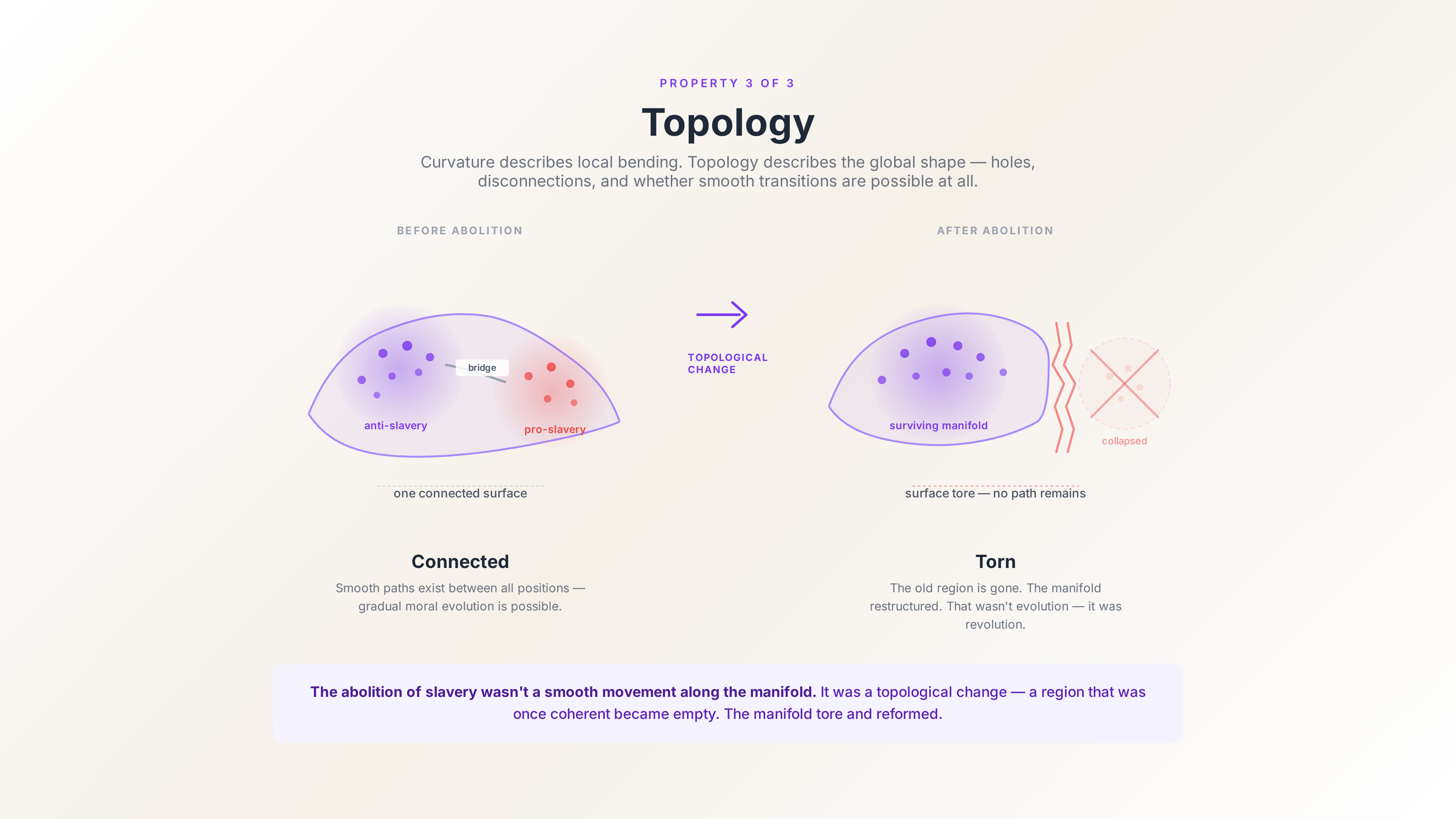
The topology of the value manifold matters because it determines what’s possible. If two regions of M are topologically disconnected — if there’s no smooth path from one to the other — then you can’t gradually evolve from one value system to the other. You have to jump. You have to undergo a moral revolution, not a moral evolution.
The abolition of slavery wasn’t a smooth movement along the manifold. It was a topological change — a restructuring of the manifold itself. A region that was once coherent (value systems that accommodated slavery) became empty. The manifold tore and reformed.
Distance on the manifold (and why it matters)
Here’s a subtle point that has massive practical consequences.
There are two ways to measure distance between value systems. You can measure the straight-line distance through the ambient space V — the Euclidean distance. Or you can measure the distance along the manifold M — the geodesic distance.
These can be wildly different.

Two value systems might be close in V — their coordinates in the full value space are similar — but far apart on M, because the path between them on the manifold goes the long way around a gap or over a ridge. Conversely, two systems that look distant in V might be geodesically close if the manifold curves to bring them together.
Why does this matter? Because RLHF uses the wrong distance.
When RLHF aggregates human preferences, it’s implicitly doing arithmetic in the ambient space V. It’s averaging coordinates. But averaging coordinates in V doesn’t respect the manifold structure. The average of two points on M might not lie on M at all — it might land in empty space, in a region where no coherent value system exists.
This is the geometric version of the argument from yesterday. RLHF doesn’t just lose information — it performs an operation (averaging in V) that’s mathematically inappropriate for the structure it’s operating on (a manifold M ⊂ V). It’s like computing the average of two cities’ GPS coordinates and expecting the result to be a city. Sometimes you get lucky. Often you get the middle of the Atlantic.
The manifold changes over time
Here’s the part most people don’t expect.
The value manifold isn’t static. It evolves. What was on-manifold in medieval Europe isn’t on-manifold now. What’s on-manifold now might not be in a century.

The mathematical structure for this is a fibre bundle. Without getting deep into the formalism: imagine a stack of manifolds, one for each moment in time (and for each culture, and for each institutional context). Each “slice” is the value manifold at that particular configuration of historical and cultural parameters. The bundle is the whole stack, plus the rules for how the slices connect to each other.
The connection on the bundle — the rule that governs how you compare values across different slices — is itself a geometric object. And it has curvature. Which means that comparing value systems across time is path-dependent: the answer you get depends on how you got there. Compare medieval and modern values via the Enlightenment and you get one answer. Compare them via colonial expansion and you get a different one.
This isn’t a bug. It’s an accurate description of why historical moral comparison is genuinely hard. The geometry captures the difficulty precisely.
So what does RLHF actually destroy?
Now you can see the full picture of what manifold collapse means.
When RLHF collapses M to a point, it doesn’t just lose “some information”…

It destroys:
The density structure — the distinction between universal values and culturally specific ones. After collapse, all values are equally absent.
The curvature — the geometry of moral dilemmas. After collapse, the model has no representation of where the hard problems are. It can’t distinguish between a question with a straightforward answer and one that lives on a knife-edge.
The topology — the global structure of what’s connected to what, what’s possible and what’s not. After collapse, the model can’t distinguish between a value shift that’s a smooth evolution and one that requires a revolution.
The geodesic distance structure — the right way to measure similarity between value systems. After collapse, the model falls back on ambient-space Euclidean distance, which doesn’t respect the manifold and produces incoherent interpolations.
The time-variation — the way the manifold evolves across history and culture. After collapse, the model is frozen at the statistical centre of its training data’s moment in time, with no representation of how values change.
That’s not a small loss. That’s the entire structure that makes values values rather than a flat list of preferences.
Why this isn’t just theory
I can already hear the objection: “This is a nice mathematical framework, but is there any evidence that transformer representations actually have manifold structure?”
Yes. And the evidence is stronger than you might expect.
Park, Choe, and Veitch proved — not hypothesised, proved — that concepts in language model representation spaces are encoded as linear directions, with a specific causal inner product that captures their geometric relationships. Choe, Park, and Veitch extended this to show that categorical concepts form polytopes (bounded geometric shapes) in representation space, with hierarchical concepts nested inside each other as faces of the parent polytope. And Templeton et al. demonstrated that sparse autoencoders can extract millions of interpretable features from production-scale models, showing that the superposition problem — multiple concepts encoded in the same dimensions — has a practical engineering solution.

None of these papers are about values specifically. But they establish that transformer representation space has rich geometric structure, and that this structure is measurable. The Geometry of Trust extends this to value representations, and that extension generates specific, testable predictions.
Which brings us to where we’re going next.
Tomorrow: the subconscious layer
If values form a manifold in representation space, and RLHF collapses it, the obvious question is: how do you measure the manifold without collapsing it?

The answer is probes. Deterministic probes that read the model’s internal representations — not its outputs — and produce signed attestations of the model’s geometric position. A subconscious layer that the model itself can’t game.
That’s Part 3: “The Subconscious Layer: Why AI Needs Deterministic Probes.”
— Jade
If you missed Part 1, start here: “The Alignment Illusion: Why RLHF Produces AI That’s Honest to No One.”
The Geometry of Trust series continues daily. Part 3 drops tomorrow.
References
Park, K., Choe, Y. J., & Veitch, V. (2024). The linear representation hypothesis and the geometry of large language models. Proceedings of the 41st International Conference on Machine Learning, PMLR 235, 39643–39666. https://arxiv.org/abs/2311.03658
Park, K., Choe, Y. J., Jiang, Y., & Veitch, V. (2024). The geometry of categorical and hierarchical concepts in large language models. Proceedings of the 41st International Conference on Machine Learning, PMLR 235. https://arxiv.org/abs/2406.01506
Templeton, A., Conerly, T., Marcus, J., Lindsey, J., Bricken, T., Chen, B., Pearce, A., Citro, C., Ameisen, E., Jones, A., Cunningham, H., Turner, N. L., McDougall, C., MacDiarmid, M., Freeman, C. D., Sumers, T. R., Rees, E., Batson, J., Jermyn, A., Carter, S., Olah, C., & Henighan, T. (2024). Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet. Transformer Circuits Thread. https://transformer-circuits.pub/2024/scaling-monosemanticity/