
The Alignment Illusion: Why RLHF Produces AI That’s Honest to No One
This is Part 1 of the Geometry of Trust series. Over the next few days, I’ll be unpacking a framework I’ve been developing that treats AI value alignment as a geometry problem — not a tuning problem.


Here’s a thought experiment.
Take every person on Earth. All eight billion. Ask them what they value most. Average the answers.
What do you get?

Not a meaningful value system. You get statistical noise. A centre-of-mass that sits in empty space — equidistant from everything anyone actually believes. A point that represents no one.
Now build an AI system optimised to sit at that point.
That, roughly, is what we’ve done.
The promise
Every major AI lab claims their models are aligned. Anthropic talks about constitutional AI. OpenAI talks about RLHF and red-teaming. Google talks about responsible AI principles. Meta publishes safety papers.
The language differs, but the promise is the same: we’ve made this thing safe. We’ve aligned it with human values.
None of them can tell you which human values.
And that’s not a minor omission. That’s the entire problem.
How RLHF actually works
Let me be clear: the engineering behind RLHF is genuinely impressive. Reinforcement Learning from Human Feedback is not trivial to implement, and the people building it are doing serious technical work.
But the core mechanic is simple, and its failure mode is structural.

Here’s what happens. You take a language model. You generate multiple responses to the same prompt. You show those responses to human raters and ask them to rank them by preference. Then you train a reward model on those rankings, and you fine-tune the language model to maximise the reward signal.
The result is a model that’s very good at producing outputs that humans rate highly.
The problem isn’t the learning. It’s the averaging.
When you aggregate preferences across thousands of human raters — who come from different cultures, hold different values, operate under different moral frameworks — you produce a reward signal that reflects the statistical centre of those preferences. The model optimises toward that centre.
And the centre, by construction, represents no individual’s actual values. It’s the mean of a distribution presented as if it were the distribution itself.
Think about what that means. If half your raters believe strongly in individual autonomy and half believe strongly in collective responsibility, the “aligned” model doesn’t navigate between those positions. It collapses them. It produces outputs that are vaguely consistent with both and deeply committed to neither.
That’s not alignment. That’s erasure with a mathematical alibi.
The result we can all feel
This is why interacting with aligned AI feels simultaneously helpful and hollow.

You’ve noticed it. Everyone has. You ask a language model about a genuinely contested ethical question — capital punishment, euthanasia, the trolley problem, anything with real moral weight — and you get the hedge. The careful “on one hand / on the other hand” response that acknowledges every perspective while committing to none.
We’ve been trained to read this as caution. As responsible design. As the model being appropriately humble about difficult questions.
It’s not.
It’s a model that’s been collapsed to a point in value space that doesn’t correspond to any coherent ethical position. It hedges because it has nowhere to stand. It’s not being cautious — it’s geometrically lost.
That phrase is important. I’ll come back to it.
Where most critiques stop — and why I go further
The standard criticism of RLHF is well-known at this point: it’s imperfect, the rater pool is biased, we need more diverse feedback, the reward signal is gameable, and so on. These are all valid. But they’re all engineering critiques. They assume the approach is fundamentally correct and just needs refinement.
I think the problem is deeper.
RLHF fails not because the implementation is flawed, but because the mathematical framework makes a category error about what human values are.
Human values aren’t a list that can be averaged. They have structure.
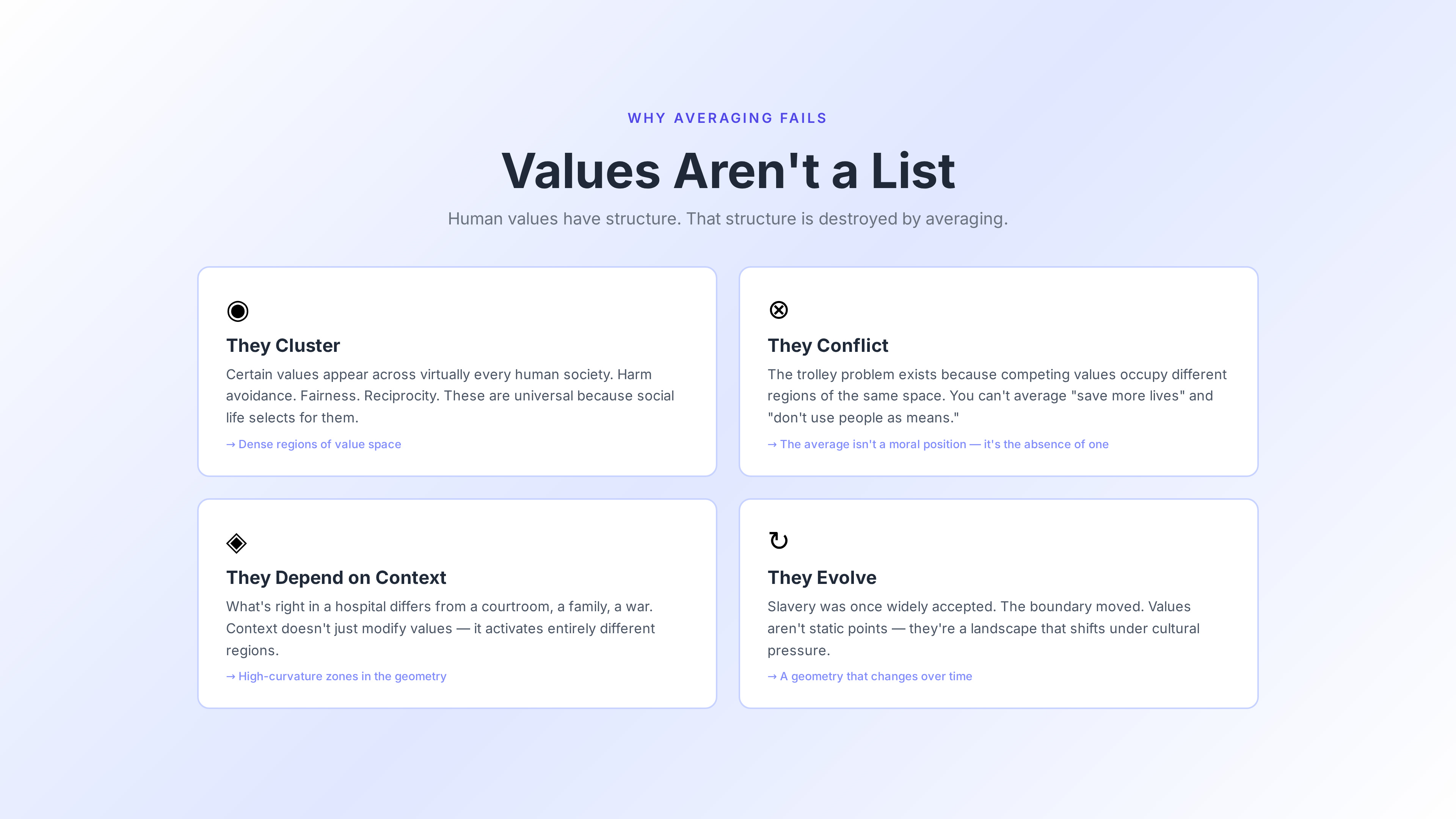
They cluster. Cultures share moral foundations — certain values appear across virtually every human society. Harm avoidance. Fairness. Reciprocity. These aren’t universal because someone decreed them; they’re universal because the structure of human social life selects for them.
They conflict. The trolley problem exists not because philosophers are pedantic, but because competing values occupy different regions of the same space. You can’t resolve “save more lives” versus “don’t use people as means” by averaging — the average isn’t a moral position. It’s the absence of one.
They depend on context. What’s right in a hospital is different from what’s right in a courtroom, which is different from what’s right in a family, which is different from what’s right in a war. Context doesn’t just modify values — it activates entirely different regions of the value structure.
They evolve. Slavery was once widely accepted; it now sits outside the boundary of any coherent modern value system. The boundary moved. The geometry changed. Values aren’t static points — they’re a landscape that shifts under cultural and historical pressure.
That structure has a name in mathematics: a manifold.
Values have shape
A manifold is a space that looks simple locally but has complex global structure. The classic example is Earth’s surface. Stand on it and it looks flat. Zoom out and it wraps around itself. You can’t represent it faithfully on a flat map without distortion — every projection sacrifices something.
I’m proposing that human values form a manifold embedded in the representation space of large language models. Not metaphorically. Literally.
The geometric structure of how a model represents concepts like fairness, harm, autonomy, and duty has measurable shape, curvature, and topology. There are dense regions where values cluster tightly — the near-universals. There are sparse regions where values diverge sharply — the culturally specific commitments. There are high-curvature zones where small changes in context produce massive changes in what’s right — the genuine moral dilemmas.
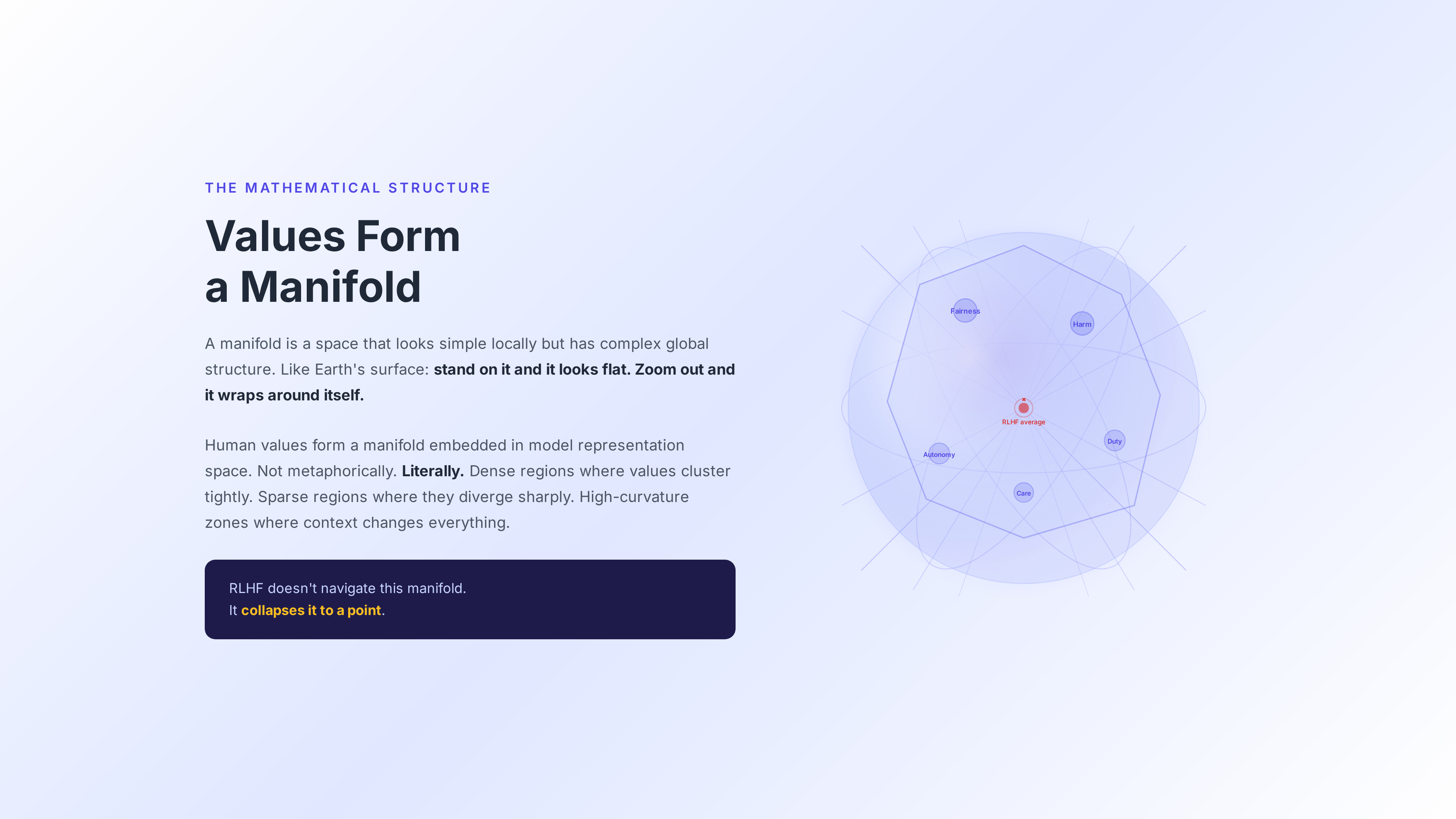
RLHF doesn’t navigate this manifold. It collapses it to a point.
Imagine averaging the GPS coordinates of every human on Earth and calling the result “where people live.” The averaged point probably lands somewhere in Central Asia. Nobody lives there. The coordinate is real. The claim is nonsensical.
That’s what RLHF does to values.
What collapse actually looks like
Let me make this concrete.
Picture a rich mountain landscape. Peaks, valleys, ridges, passes. Each peak represents a coherent value system — a set of moral commitments that hang together, that make internal sense, that people actually hold and live by. The valleys between peaks are the genuine moral disagreements that have animated human civilisation for millennia. The ridges connecting peaks are the shared moral foundations that bridge across traditions.
RLHF takes this landscape and bulldozes it flat.

It replaces the entire terrain with a single elevation: the average height. The mountains disappear. The valleys fill in. The ridges dissolve. What’s left is a featureless plain that doesn’t correspond to any actual position anyone holds.
This is why the phrase “geometrically lost” matters. A model collapsed to this point has no representation of the manifold it was sampled from. It doesn’t know the landscape exists. When you ask it a question that requires navigating the curvature of that landscape — a question about a genuine moral dilemma, where the right answer depends on which peak you’re standing on — it has nothing to draw on.
So it hedges. Not because it’s wise. Because it literally cannot see the terrain.
The point that’s off the manifold
Here’s the part that makes this worse than it sounds.
When you average points on a curved surface, the average doesn’t necessarily sit on the surface. Think about it: if you average the positions of someone standing on the North Pole and someone standing on the South Pole, the average is at the centre of the Earth. Nobody stands there. It’s not on the surface at all.
The same thing happens with value manifold collapse. The point RLHF converges to may not correspond to any coherent value system. Not a Western one, not an Eastern one, not a liberal one, not a conservative one. It may sit in the empty space between all of them — in a region of value-space where no coherent ethical framework has ever existed.
This is the incoherence problem. And it shows up every time you push an aligned model past the shallow waters.
So what’s the alternative?
This is where the Geometry of Trust comes in.
Instead of averaging values into a point, map the manifold. Don’t collapse the geometry — preserve it. Measure it. Navigate it.

Instead of asking the model what it values, measure where it sits in the geometry. Don’t trust self-report. The model’s outputs are performance — they’re what it’s been trained to say. The model’s internal representations are where the geometric truth lives.
Instead of a single alignment score, produce a geometric attestation: a measurement of the model’s actual position in value space, produced by a deterministic probe that reads the model’s representations independently of its output layer. Signed. Verifiable. Not self-reported.

I’ll unpack each of these ideas in detail over the next few days:
Tomorrow: “Values Have Shape” — what a value manifold actually is in mathematical terms, why it’s the right structure for this problem, and what it means to say a model’s value representation has curvature.
Day 3: “The Subconscious Layer” — why AI needs deterministic probes that measure internal representations rather than trusting model outputs, and what the architecture of a geometric trust probe looks like.
Day 4: “Three Testable Predictions” — the falsifiable conjectures that fall out of this framework. If the Geometry of Trust is right, these three things should be measurably true. And if they’re wrong, the framework is wrong. That’s the point.
The starting point
Here’s what I want you to take away from this piece.
The alignment problem isn’t a tuning problem. It’s not about getting the reward function right, or finding better raters, or training longer. Those are engineering improvements to a framework that makes a structural error about what human values are.
Values have shape. They have curvature. They have topology. If we ignore the shape, we’re not aligning anything. We’re averaging it into oblivion and calling the result “safe”.
The first step toward actually solving alignment is to stop collapsing the geometry and start measuring it.
Everything else follows from that.
— Jade
If this resonated, share it with someone who thinks about AI differently. The Geometry of Trust series continues tomorrow.
And if you want to argue about whether manifolds are the right abstraction for values — I’d genuinely love that conversation. That’s what this newsletter is for.