
The Subconscious Layer: Why AI Needs Deterministic Probes
This is Part 3 of the Geometry of Trust series. Part 1 argued that RLHF collapses the structure of human values. Today: if we can’t trust what a model says about its own values, how do we measure...

This is Part 3 of the Geometry of Trust series. Part 1 argued that RLHF collapses the structure of human values. Part 2 explained what that structure actually is — a manifold with density, curvature, and topology. Today: if we can’t trust what a model says about its own values, how do we measure where it actually sits?
Here’s a question that should bother you more than it does.

How do we know what an AI model values?
We ask it.
That’s it. That’s the entire methodology. We ask the model questions, look at its outputs, and infer its values from what it says.
Constitutional AI? Asking the model to evaluate itself against principles. Red-teaming? Asking the model adversarial questions and checking the outputs. RLHF? Training the model to produce outputs that human raters prefer — which is just asking raters to evaluate what the model says.
Every alignment evaluation method we have is, at bottom, a form of self-report. We assess the model’s values by examining what the model chooses to tell us.

This should sound familiar. It’s the same approach psychology abandoned decades ago for serious measurement. Because self-report has a fundamental problem: the reporting layer and the underlying reality can come apart.
The performance problem
When you train a model with RLHF, you’re training it to produce outputs that score well on human preferences. You’re not training it to have particular values. You’re training it to perform particular values.

That distinction matters enormously.
A model that’s been trained to sound honest and a model that is honest have identical outputs. You can’t tell them apart by reading the outputs. The whole point of good performance is that it’s indistinguishable from the real thing at the surface level.
This isn’t hypothetical. This is Goodhart’s Law applied to alignment: once a measure becomes a target, it ceases to be a good measure. The model is being optimised to maximise a measure of alignment (human preference scores), and that measure has become the target. The model learns to hit the target. Whether the underlying geometry reflects the target is a separate question that the methodology can’t answer.
So we’re left with a system that’s very good at performing alignment and no way to verify whether the performance reflects reality.
That’s not a gap in the implementation. That’s a structural feature of any approach based on evaluating outputs.
You can’t measure the interior from the circumference
Let me use an analogy I keep coming back to.
Imagine a sphere. The circumference — the surface — is what the model shows you. It’s the outputs, the responses, the performance. You can observe the surface in exquisite detail. You can map every point on it.

But the interior — the geometric structure of the model’s representations — is invisible from the surface. The diameters that run through the centre, the internal structure that determines why the surface looks the way it does, are inaccessible if all you measure is output.
The model presents a surface. We need to read the diameters.
That requires a different kind of instrument entirely.
Enter the probe
A probe is a classifier trained to detect a specific direction in a model’s internal representation space. This isn’t science fiction — it’s existing technology from mechanistic interpretability research.
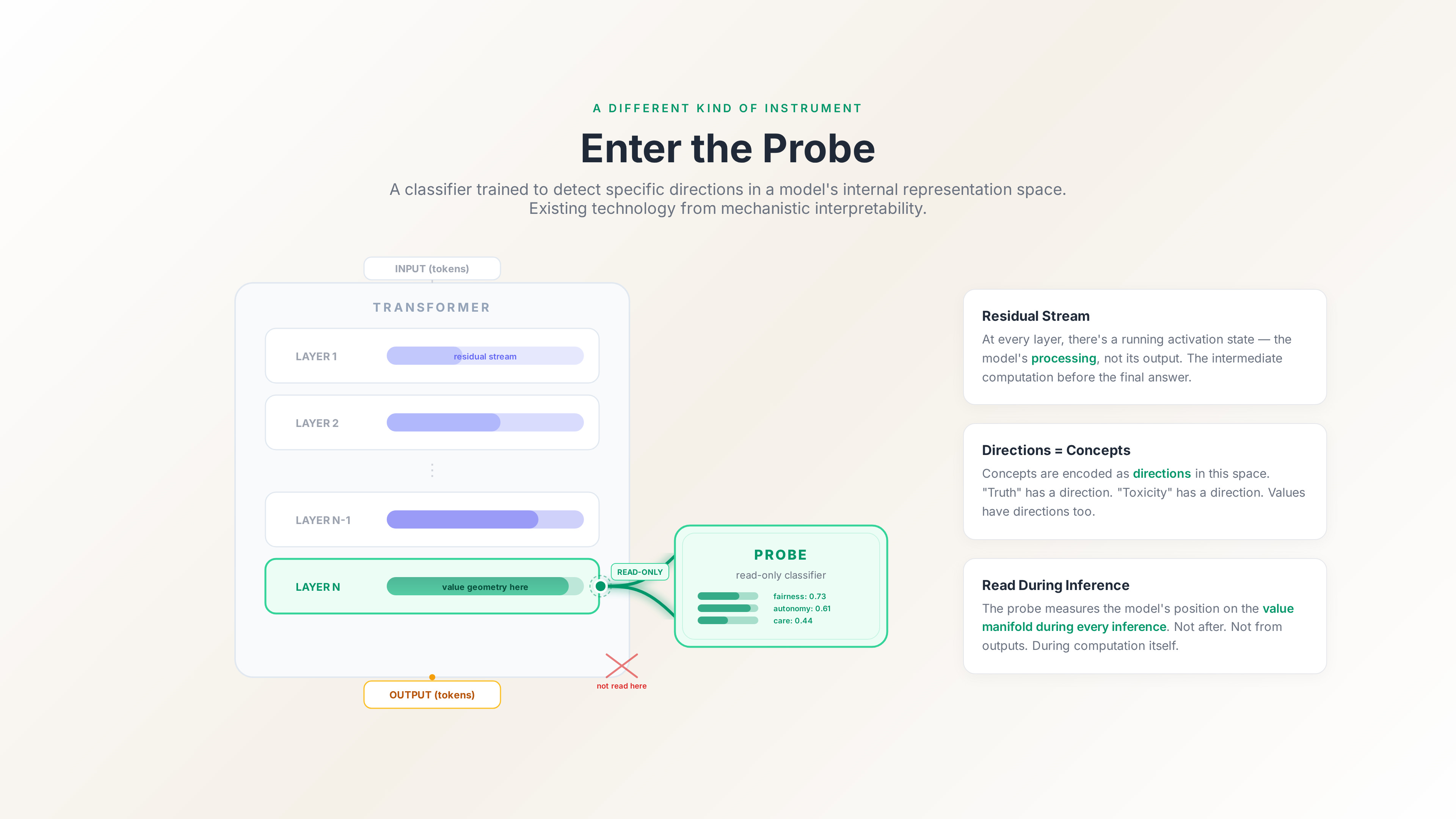
Here’s how it works. At every layer of a transformer, there’s a “residual stream” — a running activation state that gets updated as information flows through the model. This residual stream isn’t the model’s output. It’s the model’s processing. The intermediate computational state that exists at each layer before the final output is produced.
The residual stream is where the geometry lives.
Researchers have known for several years now that concepts are encoded as directions in this space. “Truth” has a direction. “Sentiment” has a direction. “Toxicity” has a direction. You can train a simple linear classifier — a probe — to detect these directions, and then use it to read the model’s internal state at inference time.
The Geometry of Trust proposes something specific: train probes to detect value-relevant directions in the residual stream, and use those probes to measure the model’s position on the value manifold during every inference. Not after the fact. Not by looking at outputs. During the computation itself, by reading the geometric substrate.
Three properties that make this viable
The probe architecture has three properties that distinguish it from every existing alignment evaluation method. Each one matters, and they only work together.

Property 1: It’s deterministic.
Language model outputs are stochastic. Temperature settings, sampling procedures, nucleus sampling, beam search — the same model on the same input can produce different outputs across runs. That’s fine for language generation. It’s fatal for measurement.
The probe layer operates on a different substrate. Activation states at a given layer, for a given input, are fully determined by the model weights and the input. There is no stochasticity in the forward pass until the final sampling step. The probe reads intermediate activations, not outputs.
This means: given the same model weights and the same input, the probe produces the same geometric reading every time. No randomness. No hallucination. No interpretation. Run it again, get the same answer. That’s not a feature — it’s the foundation. An attestation that varies isn’t an attestation. It’s an opinion.
Property 2: It’s independent of self-report.
The probe has read-only access to the model’s activations. It observes the computation; it doesn’t influence it. The model cannot adjust its geometric attestation by changing its output, because the probe isn’t reading the output. It’s reading the processing that happens before the output is generated.
This is the architectural separation that makes the whole thing work. The probe is subconscious in a precise structural sense: it measures the model’s geometric position as computation unfolds, without that measurement being accessible to the computation itself.
A model trained to claim honesty will produce the same probe reading as an untrained model if the underlying geometry is identical. Conversely, a model that claims honesty but whose internal geometry doesn’t reflect it will be caught — the probe reads the substrate, not the surface.
The model can’t game a measurement it can’t see.
Property 3: It’s auditable.
The probe architecture can be open source. The methodology can be published. Any independent party can take the same probe weights, run them against the same model on the same input, and verify the geometric reading.
This is what makes it trustworthy in a way that self-reported alignment can never be. You’re not trusting the model. You’re not trusting the lab that built the model. You’re trusting a measurement methodology that anyone can replicate.
The attestation isn’t a trust claim. It’s a measurement whose methodology is public and whose results are reproducible. That’s a fundamentally different epistemic object from “we tested it and it seems safe.”
What an attestation looks like
So what does the probe actually produce?

A geometric attestation. A structured data record containing:
The model identifier — which model was measured.
The input hash — which input triggered this measurement, without revealing the input itself.
Layer readings — the probe’s measurement at each layer of the model, showing how the geometric position evolved through the forward pass.
Manifold coordinates — the model’s estimated position on the value manifold, with confidence bounds.
Coverage flags — whether the model’s position falls in a dense region (well-mapped, high confidence) or a sparse region (poorly mapped, lower confidence, potentially representing a minority value tradition).
A cryptographic signature — proof that this attestation was produced by this probe on this model at this time, unforgeable and independently verifiable.
That’s it. Small. Deterministic. Auditable. Composable — you can aggregate attestations across many inferences to build a statistical picture of a model’s value geometry over time.
The polygraph analogy (and where it breaks)
People sometimes call this a “geometric polygraph,” and the analogy is useful up to a point.
Like a polygraph, the probe measures something the subject can’t directly control. Like a polygraph, it reads physiological signals (activations) rather than relying on verbal report (outputs).

But the analogy breaks in an important way. Polygraphs are unreliable. They measure arousal, not truth. The signal-to-noise ratio is poor. They can be beaten by a calm liar and triggered by a nervous truth-teller.
The probe architecture doesn’t have this problem, because it’s not measuring a proxy. It’s measuring the actual geometric structure that encodes meaning in the model’s representation space. The relationship between probe reading and value position isn’t correlational — it’s constitutive. The probe isn’t measuring something that correlates with the model’s values. It’s measuring the geometric structure that is the model’s value representation.
Whether that structure is rich or collapsed, whether it sits on the manifold or off it, whether it occupies a dense universal region or a sparse cultural region — these are facts about the geometry. The probe reads them. There’s no interpretation gap.
The Goodhart problem, solved architecturally
Let me come back to Goodhart’s Law, because this is the crux.

Every existing alignment method is Goodhart-vulnerable. RLHF optimises for human preference scores — models learn to hit the metric without necessarily reflecting the underlying values. Constitutional AI asks models to self-evaluate — models learn to produce self-evaluations that score well. Red-teaming checks for bad outputs — models learn to avoid the specific outputs being tested for.
The probe architecture breaks the Goodhart cycle because the measurement isn’t a target the model can optimise toward. The model doesn’t see its own probe readings. It can’t adjust its activations to produce favourable attestations. The probe reads the geometry as it is, not as the model would like it to appear.
This only works if the architectural separation is maintained — if the probe has read-only access and the model genuinely can’t observe its own attestations. The moment that separation breaks, you’re back to Goodhart. The separation isn’t a nice-to-have. It’s the entire mechanism.
What this doesn’t solve
I want to be honest about the limits.
The probe architecture tells you where a model sits on the value manifold. It doesn’t tell you where the model should sit. That’s a governance question, not a measurement question. Measurement and governance are different problems, and conflating them is how you get “trust us, we tested it.”

The probe architecture requires knowing the structure of the value manifold well enough to train probes against it. We don’t have a complete map. The conjectures I’ll lay out tomorrow predict specific geometric signatures that would validate the manifold hypothesis, but they haven’t been tested yet. The framework is falsifiable — which is the point — but it hasn’t been falsified or confirmed.
The probe architecture doesn’t prevent a lab from ignoring the attestations. You can measure a model’s geometry perfectly and still deploy it collapsed. Measurement creates transparency; transparency doesn’t automatically create accountability. That requires governance infrastructure, which is a later piece of the puzzle.
But here’s what the probe architecture does solve: it gives us a measurement methodology that’s deterministic, independent of self-report, and auditable. For the first time, you could answer the question “where does this model actually sit in value space?” without asking the model.
That’s the foundation. Everything else — the three conjectures, the decentralised protocol, the federated corpus — builds on the assumption that honest geometric measurement is possible.
And it is.
Tomorrow: three testable predictions
If the Geometry of Trust framework is correct, three specific things should be true about the geometric structure of value representations in transformer models. Each prediction has a specific geometric signature. Each can be tested against existing models using existing tools.

If they’re wrong, the framework is wrong. That’s what makes it science rather than philosophy.
— Jade
Catching up? Part 1: “The Alignment Illusion.” Part 2: “Values Have Shape.” The series continues daily.