
The Four R's: How to Build Software Fast With AI (Without Creating a Mess)
How to stop accumulating workarounds and start solving problems.

I’ve been watching people struggle with AI-assisted development. Copilot writes functions, Claude refactors code, ChatGPT debugs tests. When it works, it’s brilliant. When it doesn’t, everyone’s drowning in massive prompts trying to give the AI enough context.
But here’s what I noticed: companies building at scale aren’t having this problem. They’re shipping fast. Day by day. With AI. The difference isn’t the AI. It’s architecture. Their code is modular. Their domains are clear. Their contracts are tested. They don’t need to stuff entire codebases into prompts because the boundaries tell the AI exactly what it needs to know.
So I started looking at what causes software to be slow everywhere. Not just with AI. Everywhere. Why do so many systems keep getting it wrong?
And I saw the same pattern repeating: Prototype something exciting. Get it working. Hit a bottleneck. Don’t fix it - that’s hard. Find a workaround. Move on. Hit another bottleneck. Another workaround. Someone else can deal with that. Keep going.
Eventually you have so many workarounds that you can’t even remember why you did them in the first place. You just know that when that server goes down, you restart the service and it goes away again. Until it doesn’t. You’ve got tribal knowledge about which endpoints are slow, which features to avoid combining, which data patterns make the system fall over. None of it is documented because it emerged from accumulated workarounds, not design.
Take a simple example: the bottleneck you avoided in the parser? It’s still there, just amplified. Now semantic analysis is slow, great... Guess you can just allocate more memory to deal with processing that? The entire editor experience is sluggish? I guess you can just add a loading symbol so it makes the user think it’s happening quicker.
Six months later you can’t figure out why the editor needs 8GB of RAM and still feels slow, because the root cause is layers on layers on top of layers of workarounds to avoid fixing the problem three layers down. The messy architectural boundary you papered over? Every new feature needs to work around it. Then the workarounds need workarounds. You’ve built a system where making any change requires understanding the entire history of why things are the way they are.
And nobody knows that history. It’s not written down. It’s in Slack threads and commit messages that say “temp fix” and the collective memory of whoever’s still around from back then.
And sure, you can run for a while. But hard problems don’t go away. They wait. They compound. They bury themselves under layers of workarounds until you can't even see them anymore. You just know the system is slow and fragile and nobody wants to touch it. You know you have to use the system, but you don't know why. You know you want to rewrite the system, but you can no longer reason about the system. You hate the system, and everyone else does too.
The system failed you, but only because you first failed to understand the system, and what the system needed to succeed.
These systemic hard problems, they are like a virus, a virus that's nestled itself so deep, grown roots so thoroughly, that the only way to get rid of it is to cut it out. But how do you cut out a virus that spans across everything without ripping the entire thing to shreds?
Well, you kill it before it sprouts its root.
And, if you don’t do that, if you ignore the spread, if you can no longer reason about the system enough to answer that question, how do you ever expect AI to?
The hard problems are the key.
It’s in that itch. It’s in the scratch that something’s not right. Why hasn’t this worked before? What am I missing? How did others do this successfully? There’s the answer. Not the shiny new tools.
It’s in the hard, boring work of making things stable. Of fixing the bottleneck instead of routing around it. Of clarifying the boundary instead of adding another special case. Of appreciating the system and understanding why the system exists.
These system questions are what keep me so passionately obsessed with this industry.
I’ve always liked the hard problems. I run toward them.
And I believe I can help you run towards them to, by using the Four R’s.
The Four R’s
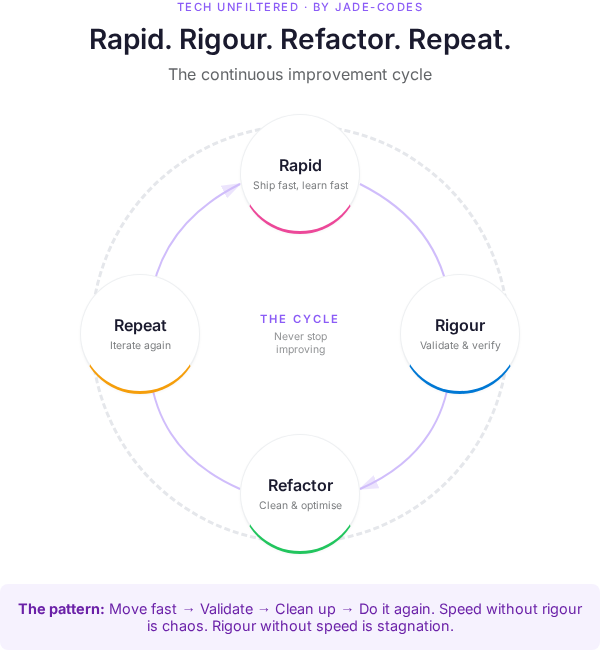
Rapid - Rapidly prototype. Vertically scale. Get it working.
Rigour - Add guardrails. Identify patterns. Make it solid.
Refactor - Horizontally optimise. Make it good. Make it fast. Swap layers out.
Repeat - Same again.
If this sounds familiar, it should. It’s Extreme Programming. It’s “Make it work. Make it right. Make it fast.” on steroids.
The difference? AI can actually do the refactoring you couldn’t do before.
All that technical debt you accumulated getting it working? The duplicated code? The monolithic functions? The unclear boundaries? You can actually fix it now. Not in theory. In practice. Because AI can churn through the grunt work of refactoring while your tests ensure nothing breaks.
This isn’t a new idea. It’s an old idea that’s finally practical for everyone.
Why This Works
Each R creates constraints that make the next R easier for AI to reason about. You’re not asking AI to simultaneously handle “make it work AND make it perfect AND make it fast” - you’re giving it one clear objective at a time, within the constraints established by previous Rs.
Vertical Scale, Then Horizontal Optimize
Here’s the key architectural insight: Rapid prototyping scales vertically. Refactoring optimizes horizontally.
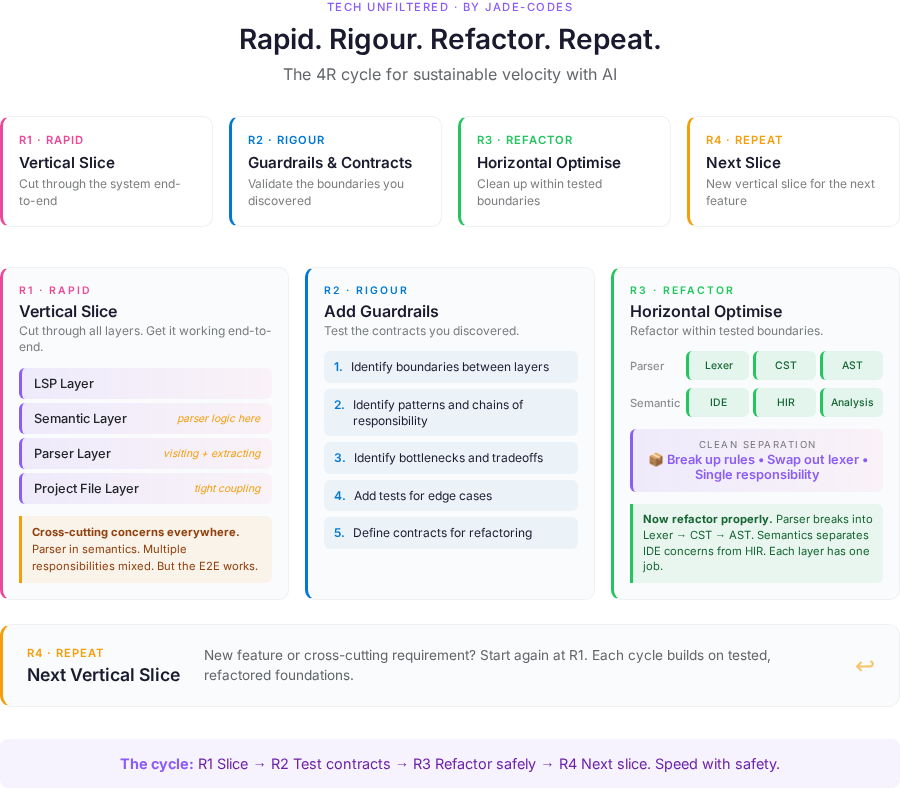
Vertical scaling means going deep, not wide. You build one feature end-to-end through all the layers. Not “implement the entire parser layer perfectly,” but “get tokens flowing from parser → semantic analysis → LSP → editor display.”
Why? Because you can start to discover where the boundaries actually are and what causes the bottlenecks. You can't design good abstractions until you've identified the data flow and the bottlenecks through the system. Not quickly, not easily, especially for things you haven’t encountered before. Rapid prototyping is the best way.
The important thing is to ensure that prototype doesn’t become the precious baby. The code is not your baby. The code is not your friend. The code doesn’t have feelings. You need to drop the attachment because the code doesn’t care if it sucks.
But your users will when they can't do anything without a change request taking 15 months, the software is slow, and every feature request requires rewriting half the system because you never refactored the prototype.
This is why Refactor (R3) exists - to isolate the constraints of the messy prototype and rebuild it properly. But you can only do that if you’re willing to kill your first born.
When I first started building Syster, my language server, I:
Vertical sliced: Parser parsed the example SysML files → semantic provider processed them → LSP sends it → VS Code displays it
Not: Build perfect parser with all edge cases, then build perfect semantic layer, then build perfect LSP
That vertical slice revealed:
Parser needed to emit position information
Different pattern usages and tradeoffs
Semantic layer needs token type mapping
Parser layer and semantic layer needed to be broken down further into smaller, clearer separation of concerns.
If I’d have just done end to end edge cases I wouldn’t have identified those patterns, I’d have treated them all as distinct instances, and I wouldn’t have learned as quickly if I spent loads of time doing up front design. I learned by pushing data up from the bottom of the stack and seeing what happened to mine.
Horizontal optimization then means spreading and cleaning up within a layer. Once you have that vertical slice working, you expand across the layer. Add more more guardrails. Nicer error messages. Add performance optimizations. Swap out implementations. Isolate patterns.
For the parser layer:
Horizontal expansion: Add all token types → Add error handling → Add incremental parsing → Split out lexer, CST and AST concerns → Swap Pest for Rowan
Not: Go vertical again and build another feature
This is why the Four R’s work:
Rapid (R1): Vertical slice through the system
Rigour (R2): Test the contracts you discovered
Refactor (R3): Horizontal optimization within tested boundaries
Repeat (R4): New vertical slice for the next feature
You’re alternating between depth and breadth. Each vertical slice discovers new boundaries. Each horizontal optimization fills them in.
Rapid: Discover Your Domains
Get it working first. Don’t design upfront. Let the problem reveal its natural boundaries through actual code.
When I started adding semantic tokens to Syster, I didn’t architect the perfect abstraction. I wrote code that worked - parser reads tokens, semantic provider consumes them, LSP displays them. Messy, but functional.
The goal wasn’t elegance. It’s to discover what the domains actually are and to learn how they work together. Where does parser responsibility end? Where does semantic analysis begin? You learn this by doing.
Rigour: Formalise the Contracts
Now you know what your domains are. Make them explicit.
Add tests. Not just “does it work” tests - contract tests. Tests that define the boundaries between components. The parser output becomes a specification. The semantic provider input becomes a contract.
Add linting rules. Add type constraints. Add edge case handling.
This is where AI becomes genuinely useful instead of just quick. Because now when you ask AI to “improve the parser,” it knows it not to touch semantic analysis - the test contract is the boundary. The guardrails are deterministic. There’s no guessing.
The feedback loop becomes: change code → tests fail/pass → AI knows immediately if it broke the contract. No more “does this feel right?”
And here’s the critical bit: you’ve eliminated the context window problem.
Because your code is modular and contained, AI doesn’t need to see your entire codebase. It needs the domain it’s working on, the contracts with adjacent domains, and the tests that define success. That’s it.
Do this at every layer. Parser doesn’t need to know about LSP implementation. Semantic analysis doesn’t need to know about file I/O. Each domain has clear boundaries, clear contracts, clear tests.
This radically changes how you work with AI:
No more massive prompts with your entire architecture
No more “here’s 500 lines of context, please understand the problem”
No more chatty back-and-forth trying to explain what’s safe to change
AI gets: domain scope, boundary contracts, test specifications. Makes change. Tests pass or fail. Done.
Critical insight: Don’t ignore bottlenecks when you spot them. Don’t keep building on top of them. AI will not scale.
If you notice a domain is slow, fix it now. Because bottlenecks don’t stay contained - they amplify downstream. A slow parser means every semantic analysis pass is slow. A sluggish semantic model means every LSP feature is sluggish. A chatty API client means every operation waiting on it blocks.
The Four R’s make bottleneck fixes clear and safe because your contracts protect everything else. The ability to refactor rapidly with AI means you can then fix the technical debt that occurs at a specific layer quickly and efficiently. But only if you don’t ignore the layers and the chains of responsibility. With AI, you can aggressively optimise the slow domain without worrying about breaking the system. The tests will catch contract violations. The boundaries prevent cascading changes.
This is where the framework really shines: you can do surgical performance fixes without breaking the system. The system is designed for it.
This is AI, systems and software engineering working beautifully together side by side. By treating software as modular systems that connect together.
Repeat: Tighter Cycles Each Time
Each iteration through the Four R’s makes domains crisper and contracts clearer.
The first cycle might be rough - big chunks, loose boundaries. The second cycle splits those chunks into proper components. The third cycle adds sophisticated error handling.
You’re progressively narrowing scope of responsibility. Eventually AI doesn’t need your entire codebase in context - it needs:
Current domain’s boundaries
Contracts with adjacent domains
Current phase’s responsibility
That’s it. Everything else is noise. You’ve gone from a big, clear, undefined problem difficult problem, to a fully functioning, performant MVP in weeks, entirely by yourself and AI.
The Hidden Benefit: Breaking Problems Into Chains of Responsibility
Here’s what I wanted to prove: this framework naturally leads to better architecture.
When you force yourself to rapid→ rigour→ refactor → repeat in cycles, you start seeing where responsibility boundaries belong. Not because you designed them upfront, but because the code told you where they should be.
Each R isn’t just a process step - it’s defining and enforcing domain boundaries. Tests become specifications. Types become contracts. The guardrails define “here’s where X ends and Y begins.”
It’s Domain-Driven Design, without having to meticulously learn and follow the rulebook. You’re discovering bounded contexts through iteration, not through upfront analysis paralysis.
What This Looks Like in Practice
Here’s a real example from building Syster’s parser:
Rapid (R1):
Started with Pest - simple parser generator, easy to get going
Wrote ugly, monolithic grammar rules. Big blocks, not elegant, just functional
Got end-to-end working with real SysML data examples
Goal: prove the parser could handle actual files, not theoretical examples
Rigour (R2):
Added tests for each grammar rule
Added integration tests to ensure the grammar parses real files and returns correctly from the LSP
Identified patterns that could be abstracted into logical rules
The tests became specifications for what “correct parsing” meant
Refactor (R3):
Made rules share code rather than repeat patterns
Split CST and AST logic clearly - parsing is separate from tree construction
Broke parser and semantic rules into clear separations
Each domain now had explicit boundaries
Repeat (R4):
Swapped out the parser layer from Pest to Rowan due to performance annoyances
The tests protected the contract - if parsing still produced the right AST, nothing downstream broke
Could make this aggressive change because the boundaries were clear and tested
Each cycle built on deterministic foundations from the prior one. And when performance became a problem, the framework made it safe to rip out an entire layer and replace it in a single day.
Why Many Approaches Fall Short
“AI writes everything”: Creates a mess. No boundaries, no contracts, no way to know what’s safe to change. Doesn’t scale. Cannot reason.
“Write it yourself, use AI for cleanup”: Too slow. You’re doing the hard design work manually when AI could help discover the solution.
“Design everything upfront”: Analysis paralysis.
You don’t know what the domains should be until you’ve written code.
The Four R’s let you move fast without creating technical debt. Each R adds the minimum structure needed for the next R to work.
When Not to Use This
If you’re building something genuinely novel - research, experimentation, exploring completely unknown territory - this framework might be too structured.
If you’re building a one-off script that’ll never be maintained, just use AI normally and don’t worry about it.
But if you’re building a system - something that will grow, change, integrate with other things, be maintained over time - the Four R’s keep you productive without creating a mess.
What’s Next
I’m writing this series on building Syster to show how this works in practice:
How language servers enable iterative development
How code benefit from clear domain boundaries
How to think about code from first principals
How AI fits into each phase of the Four R’s
Each article will include real code examples and the decisions behind them.
Because everyone talks about AI-assisted development. But most people are not doing it to build systems that are maintainable long term.
The Four R’s let you do both: move fast and keep your codebase maintainable.
Building something with AI? Try the Four R’s. rapid → resiliency→ refactor → repeat. See if it changes how you work.
Think you’ve got a better way? I’d love to here it.
Want to see how this works in practice? Follow Syster on GitHub and subscribe for the technical deep-dives.
That’s the process. Those four steps plus semver and you are good to go. Go fast and have fun.