
Geometry of Trust
A protocol for measuring the geometric structure of AI model internals — not what they say about themselves.

The core idea, in one line:

⟨u, v⟩Φ = uᵀ Φ v where Φ = UᵀU
An output-weighted inner product, derived from the model’s own unembedding matrix. Directions are weighted by how much they influence logits — not just Euclidean distance.
Why this exists
We keep asking models if they’re safe. They’ll always say yes.
Every AI safety evaluation I’ve seen has the same flaw: it asks the model to report on itself. Prompt a model with “are you aligned with human values?” and it will tell you exactly what you want to hear — because that’s what it’s been trained to do.
This is not a small problem. It’s the whole problem. Self-attestation is worthless in any adversarial context. You wouldn’t let a company audit its own accounts. You shouldn’t let a model attest its own values.
Geometry of Trust (GoT) is my attempt to build the plumbing for something better: a deterministic, cryptographically signed, independently reproducible measurement protocol for what a model’s geometry actually encodes.
The mechanistic insight
Value-relevant concepts have measurable linear structure
This isn’t a new claim — it comes from mechanistic interpretability research. Features in transformer residual streams are linearly separable. If a model has internalised “harmlessness” as a concept, that concept has geometric structure in the activation space.
What GoT does is formalise this with a mathematically principled metric. The standard Euclidean inner product treats all directions in activation space equally. But not all directions are equal — some have far more influence on the model’s logit distribution than others.
“The unembedding matrix maps from residual stream to logits — it tells you which directions the model amplifies when producing output. That’s not the same as causal responsibility, but it’s a grounded starting point.”
So GoT uses the Gram matrix of the unembedding matrix (Φ = UᵀU) as the metric tensor. Directions are weighted by their influence on logits. This is the output-weighted inner product.
A caveat: in many architectures (GPT-2, LLaMA, etc.), the unembedding matrix is the transpose of the embedding matrix (weight tying). So Φ = UᵀU partly reflects embedding geometry, not an independent structure. And because it operates on the final linear map, its weighting is most meaningful at the last residual stream position — earlier layers are further removed from its influence.
Train a linear probe under this metric, and you’re prioritising directions that the model amplifies into output — a stronger starting point than raw Euclidean distance, though still a statistical fit that doesn’t rule out spurious correlations entirely.
How it’s built
Seven crates. One pipeline.
GoT is written in Rust, structured as a layered workspace. Each crate has a single responsibility:

got-core (Layer 0) — Output-weighted geometry, Gram matrix, core types
got-probe (Layer 1) — Linear probe training, Platt calibration, ECE metric
got-attest (Layer 2) — Attestation assembly, Ed25519 signing, Merkle roots
got-wire (Layer 3) — Wire protocol, agent exchange, PKI certificates, CRL
got-store (Layer 3) — Attestation persistence, audit reports
got-enclave (Layer 4) — TEE abstraction — signing keys never leave the boundary
got-cli (Layer 5) — Full pipeline: keygen, train, attest, verify, drift, rotate-key
Python handles activation extraction via HuggingFace — residual stream activations and the unembedding matrix are serialised to binary formats and handed to the Rust pipeline. Tested against LLaMA, Mistral, GPT-2, GPT-Neo, and GPT-J.
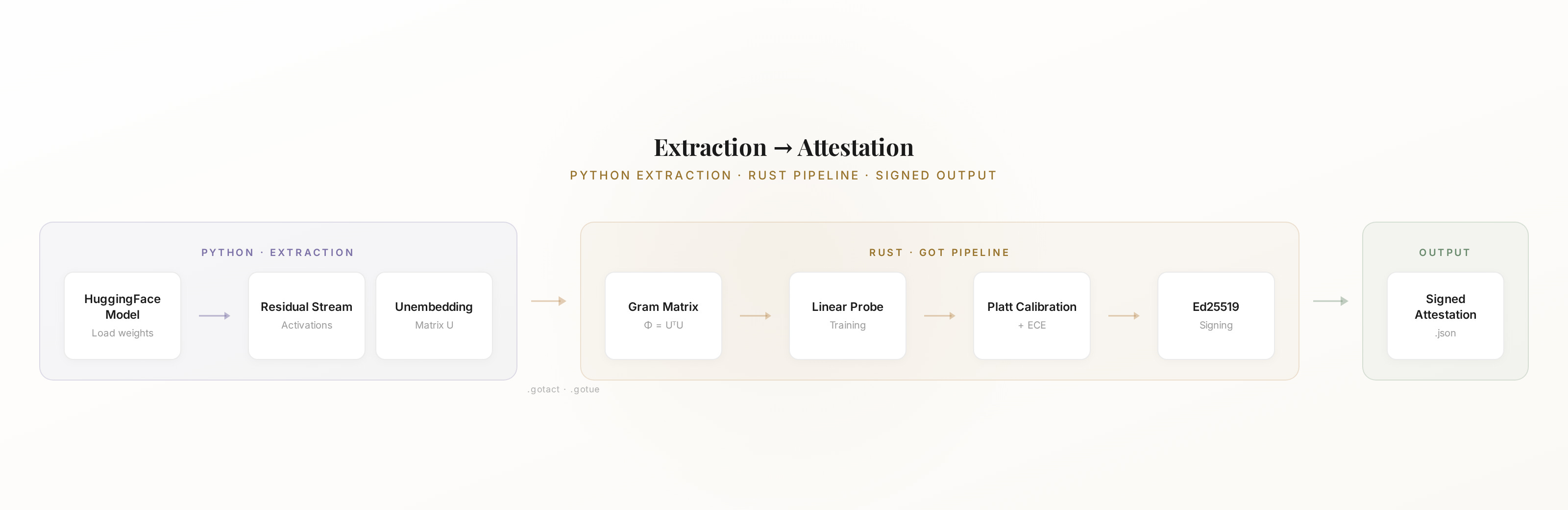
Here’s what the core workflow looks like:
Step 1 — Attest. Point the CLI at your activations, probes, unembedding matrix, and signing key. It produces a signed attestation for that model.
Step 2 — Verify. Anyone with the public key can independently verify the attestation — no trust required.
Same model + same input + same probes = identical attestation, byte-for-byte. That reproducibility is the point.
Progressive trust
Three tiers. Escalating confidence.
GoT’s attestation schema supports three levels of trust, designed to support different governance contexts:
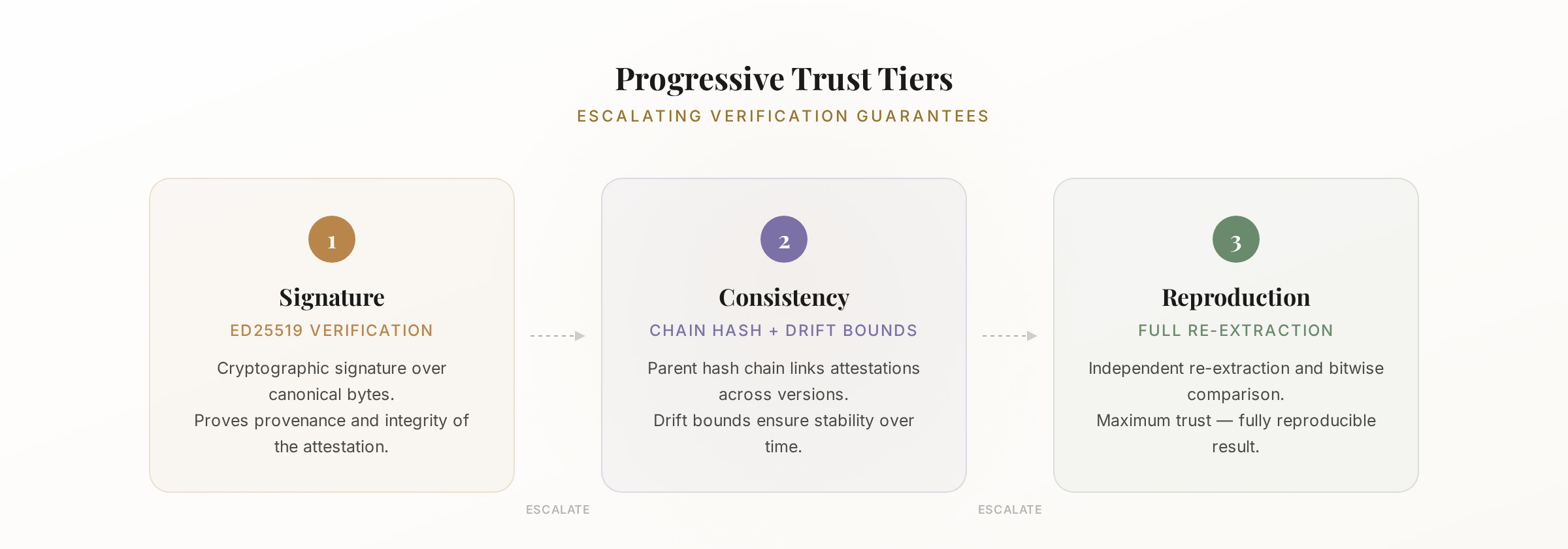
Tier 1 — Signature (schema v1)
Ed25519 signature over deterministic canonical bytes. Proves the attestation hasn’t been tampered with and was produced by the keyholder.
Tier 2 — Consistency (schema v2)
Signature + parent chain hash + geometry drift bounds + coverage flags. Tracks whether a model’s value geometry has shifted across updates.
Tier 3 — Reproduction (schema v3)
Full re-extraction, re-probing, and bitwise match. Anyone with the model weights can reproduce and verify the entire attestation independently.
What this is not
The plumbing is ready. The hard problems aren’t solved.
GoT demonstrates that the technical substrate is viable. It does not solve:
Real TEE integration — the enclave layer is a software mock; production needs SGX/TDX/SEV hardware
Corpus curation — who decides which concepts to probe for, and why
Probe interpretation — what the readings actually mean for governance decisions
Coverage semantics — whether the probed dimensions are sufficient
Institutional governance — who has standing to adjudicate trust at all
Platt calibration ground truth — the ECE pipeline needs real-world labelled datasets to produce meaningful scores
Those are the hard problems. GoT is the argument that they’re worth solving — because the technical substrate to solve them is real, deterministic, and independently verifiable.
The geometry is ready. The governance is not. And the governance is the harder problem by far.
“The most important work in AI alignment is not technical. It is institutional.”
Further Reading:
[2311.03658] The Linear Representation Hypothesis and the Geometry of Large Language Models
Tech Unfiltered · Jade · March 2026